Field-level provenance in AI underwriting: the audit standard CUOs need in 2026


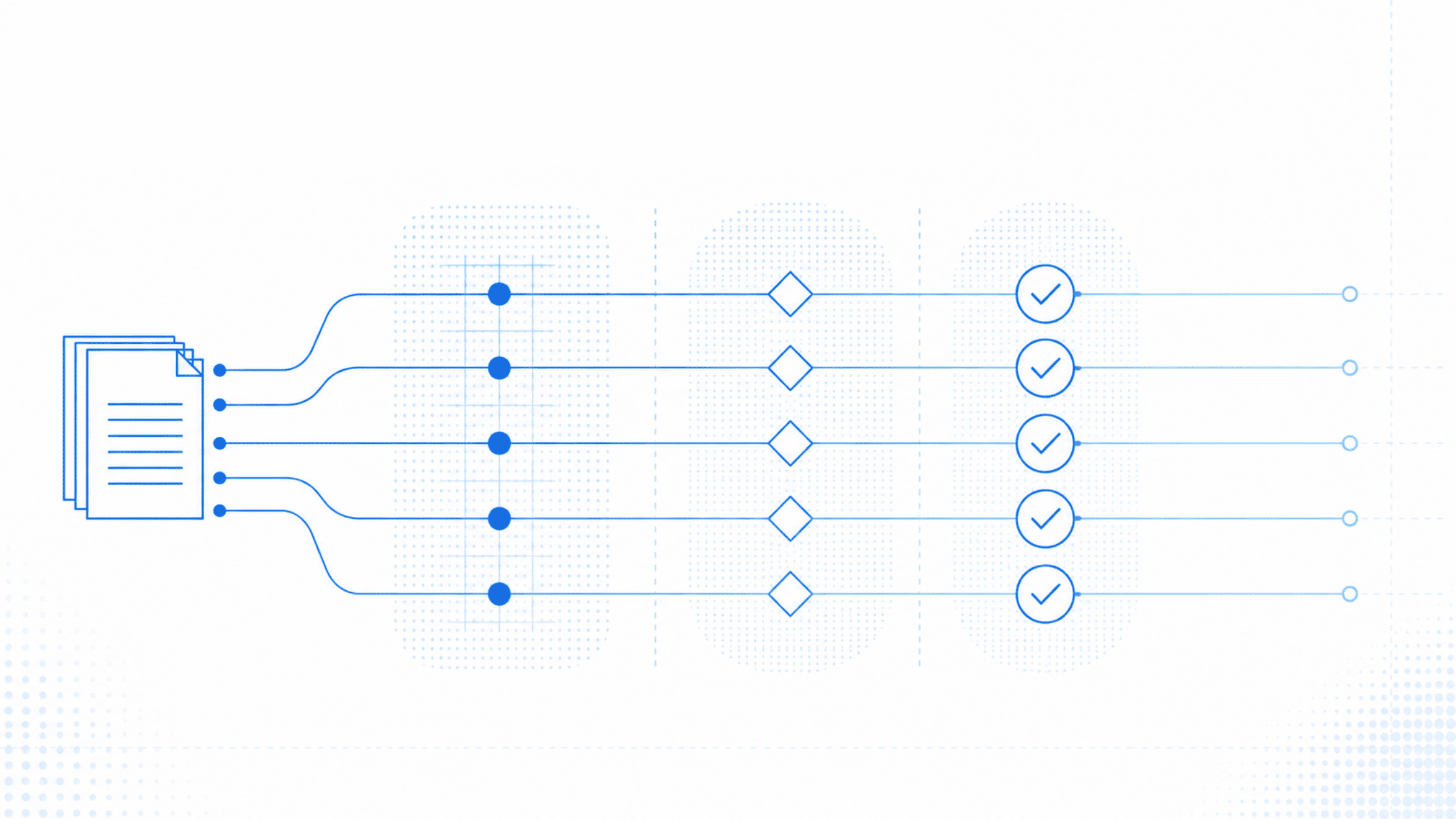

- A 95 percent extraction accuracy figure is not the same as a defensible underwriting decision. Without field-level provenance, accuracy is a marketing number, not an audit artifact.
- Frontier large language models read fluently but rarely produce source-linked outputs at the field level. Carriers that route those outputs into rating, clearance, or referral logic absorb the regulatory and reinsurance risk on every decision.
- Field-level provenance means each extracted value carries the document, page, coordinate, extraction confidence, transformation logic, validator outcome, and reviewer attestation that produced it. This is the audit standard CUOs need before an AI underwriting workflow can scale.
- The Pibit.AI three-layer architecture (specialised extraction, agentic quality assurance, human expert review) was designed so that every value in CURE™ is source-linked by default. That is what allows the 100 percent contractual accuracy guarantee.
- This piece walks through why provenance matters in 2026, an eight-point provenance rubric for evaluating any AI underwriting vendor, and the operational unit economics of getting it right on a $500M GWP carrier.
Why provenance is the 2026 question, not accuracy
The most important sentence in any AI underwriting evaluation in 2026 is the one that almost never gets asked. It is not "what is your accuracy?" It is "show me, for any field on any submission, exactly where it came from, how confident the model was, what validators ran on it, and who attested to it."
That single question separates a vendor demo from a production system.
Accuracy is the headline that vendors lead with. A model is benchmarked on a held-out test set, hits 95 percent or 97 percent, and is described as production-ready. The number is real, but it is the wrong number. A submission packet is not a benchmark. It is a heterogeneous bundle of broker emails, ACORD forms, loss runs, statements of values, vehicle schedules, supplemental questionnaires, and one-off carrier addenda. Field accuracy on a benchmark does not predict field accuracy on a 200-page commercial property submission with eleven attachments and a forwarded thread. And even if the field value is right, an underwriter who cannot trace it back to a source line on a source page in a source document cannot defend the resulting decision in a regulatory exam, a reinsurance treaty audit, an internal QA review, or a litigated claim.
Field-level provenance is what closes that gap. It is the property that, for every value the system produces, the lineage is recorded at the granularity of the field itself. Document, page, coordinates, extraction step, model version, confidence score, validator outcomes, transformations applied, and the human or agentic reviewer who attested to the value are all captured and queryable.
The 2026 market environment makes this no longer optional.
First, the regulatory floor moved. The NAIC Insurance Data Security Model Law has been adopted in the majority of states with active insurance markets, and several departments of insurance have updated examination protocols to include AI governance, model risk management, and audit trail expectations. The NYDFS Part 500 amendments effective in 2024 and 2025 added explicit governance and documentation expectations for any technology that informs underwriting or claims decisions. State adoption of the NAIC AI Model Bulletin during 2024 and 2025 reinforced that carriers and MGAs are expected to evidence, not assert, the integrity of AI-influenced decisions.
Second, the rate environment changed. The 2026 commercial P&C outlooks from the Insurance Information Institute and S&P Global describe a softening market in middle market property and casualty, sustained loss cost pressure in commercial auto, and continued severity in liability. In a softening market, hit ratio and broker turnaround time are decisive, and the only way to move faster without giving up underwriting integrity is to push more of the data assembly onto a system that can evidence its own work.
Third, reinsurance treaties have begun asking for it. Treaty audits and renewal questionnaires increasingly require carriers to demonstrate the data integrity behind ceded portfolios. A field-level audit trail is the only practical answer.
Fourth, internal model risk management policies caught up. Carriers that already operate model risk management programs for pricing and reserving have extended those programs to AI-influenced underwriting workflows. Those programs require evidence of input integrity, not assertions about it.
Together, those four shifts mean the question for 2026 is no longer "is the AI accurate?" The question is "can you produce, on demand, the chain of evidence behind every value that touched a decision?"
That is what field-level provenance answers. Carriers that cannot answer it operate on borrowed time.
What field-level provenance actually means
Provenance is one of those words that sounds heavier than it is. The simplest way to think about it is to imagine a regulator, a reinsurer, a chief actuary, or a defending counsel asking the question that matters most. "Where did this number come from?" A system with field-level provenance answers that question for every field on every submission, on demand, without anyone having to dig.
A complete field-level provenance record contains, at minimum, the following nine elements.
1. Source document identity. The original file as received, including its hash, name, mime type, and broker submission identifier. Not a normalized copy. Not a parsed string. The actual file the underwriting team received.
2. Source page and coordinate. The page number and the bounding box on that page where the value was located. For email-native fields, the message identifier and the offset within the body, subject, or header. For attachments, the attachment identifier inside the parent submission.
3. Extraction model and version. The specific model and version used to extract the value. Not the model family. The exact version, with a build hash recorded so that the extraction can be replayed if needed.
4. Extraction confidence. A field-level confidence score that reflects the model's calibrated uncertainty for that specific value, not a document-level or batch-level number. Confidence must be calibrated, meaning a score of 0.92 actually corresponds to a 92 percent probability of correctness in production conditions.
5. Transformation lineage. Every transformation applied between the raw extraction and the final value. Date format normalization, currency conversion, text-to-number coercion, address standardization, VIN decoding, NAICS or SIC alignment, geocoding. Each step must be reversible to the prior representation.
6. Validator outcomes. The result of every rule, agentic check, or cross-field validation run on the value. Whether the value reconciled against another field on the same submission, against an external authoritative source, or against historical data on the account.
7. Reviewer attestation. If the value was reviewed, the identity of the reviewer (human or agent), the timestamp, and the action taken. If the value was auto-accepted on the basis of confidence, that decision rule and the confidence threshold in effect at that moment.
8. Output destination. Every downstream system that received the value, including the rater, the policy administration system, the workflow platform, and any analytics environments. This is what allows a carrier to recall and remediate any value that was later found to be incorrect.
9. Time and immutability. The record must be timestamped and write-once. A provenance record that can be edited after the fact is not a provenance record.
A vendor that does not produce all nine elements at the field level is not producing audit-grade output. They are producing demonstrable accuracy at best, and assertion-based accuracy at worst.
The reason this matters is that real submissions break down at exactly the seams a benchmark cannot reach. A loss run carrier name appears in three different formats across attachments. A statement of values has an outdated occupancy code that a broker forgot to update. An ACORD form lists an effective date that contradicts the cover email. A vehicle schedule has VINs that decode to a different year than the broker recorded. In every one of those cases, the right answer is not "the model picked the most likely value." The right answer is "the system surfaced the conflict, recorded the evidence, and asked a human."
That outcome only happens when provenance is field-level and end-to-end.
Why frontier models alone do not produce audit-grade provenance
A common assumption in 2026 is that a sufficiently capable frontier large language model, prompted carefully, produces provenance for free. It does not. There are four structural reasons.
The first is that frontier models are trained for fluent generation, not for source-linked extraction. They will read a 100-page submission and produce a coherent summary, and they will often surface specific values. But the values come back as text strings, not as references to coordinates on pages of source documents. The model has no native concept of a source location, and post hoc reconstruction of the source position is approximate at best.
The second is that the confidence signals frontier models produce are not calibrated to underwriting field accuracy. Token-level log probabilities and self-reported confidence values do not, in production conditions on real submissions, correspond to the probability that a specific extracted field is correct. Carriers that route extraction outputs into clearance or rating logic on the strength of self-reported confidence absorb model miscalibration risk on every account.
The third is that frontier models do not natively perform the cross-field reconciliation that real submissions demand. Loss run named insured cross-checked against broker email signature, ACORD form effective date cross-checked against cover email, statement of values total insured value cross-checked against rating output, vehicle count cross-checked against schedule attachment, and so on. Each of these is a discrete validation that requires deliberate orchestration. A monolithic prompt is not orchestration.
The fourth is that frontier models do not, by themselves, produce write-once audit logs. The output is whatever the model returned that turn. If the model is rerun, the output may differ. Stable, queryable, immutable provenance is a property of the system around the model, not of the model itself.
This is why the architecture matters more than the model. A production-grade AI underwriting system uses the right model for the right task, but the provenance, validation, and human attestation layers are first-class components. Without them, the model is generating outputs that look correct, not outputs that can be defended.
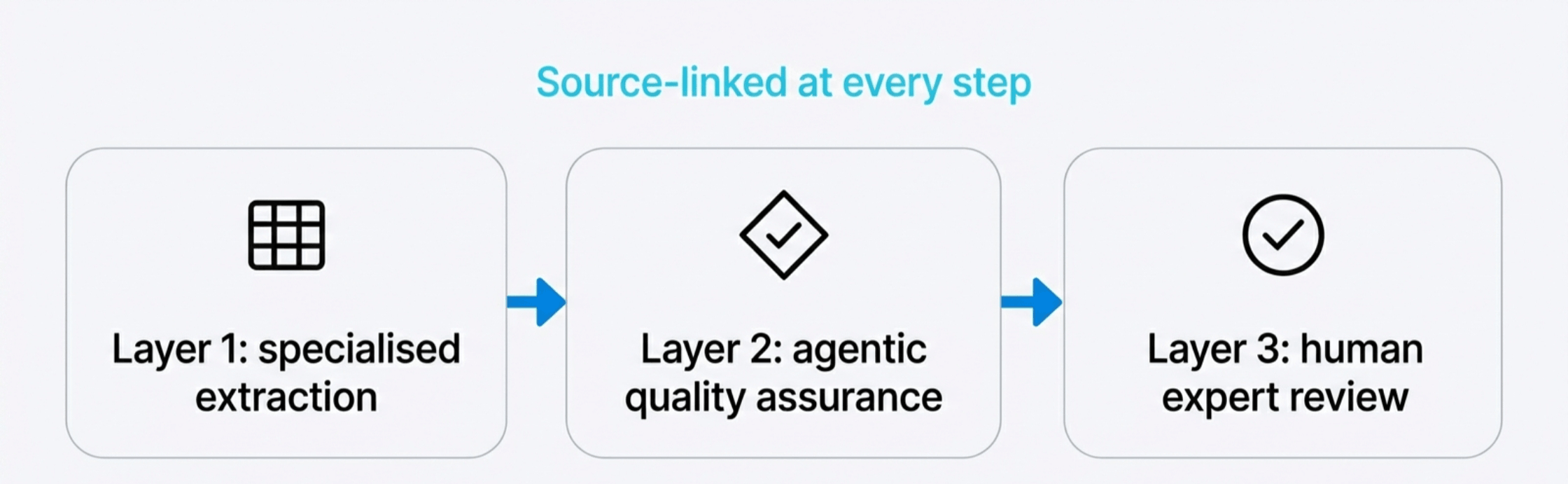
The Pibit.AI architecture, explained at the field level
The Pibit.AI CURE™ platform was designed so that every value it produces is source-linked by default. Three layers work in sequence and combine to produce the 100 percent contractual accuracy guarantee.
Layer 1: Specialised extraction. Insurance-native extraction models, tuned per document family (loss runs, ACORD forms, statements of values, vehicle schedules, broker emails, supplemental questionnaires), run with template-agnostic logic that does not break across hundreds of broker formats. Every extracted value is bound to a coordinate on a page of a specific source document at the moment of extraction, and the binding is captured in a write-once record. Confidence scores are calibrated against held-out validation sets that mirror production document distributions, not benchmark distributions.
Layer 2: Agentic quality assurance. Agentic services run cross-field, cross-document, and cross-source validations against every extracted value. Loss run named insureds reconcile against broker email subject lines and ACORD applicant fields. Statement of values total insured value reconciles against per-location values. ACORD effective dates reconcile against cover emails and policy term language. Vehicle schedule VINs decode and reconcile against the broker-stated year and make. External authoritative data (OSHA, SAFER, public filings, hazard registries) cross-checks where appropriate. Every validation outcome is recorded with the specific rule that was applied.
Layer 3: Human expert review. Insurance domain experts review any value that did not clear the agentic layer with sufficient confidence. The review is recorded with reviewer identity, timestamp, and action, and is bound to the same provenance record as the extraction and validation. Reviewers are not labelers. They are insurance specialists who understand commercial property, commercial auto, workers compensation, and general liability submissions.
The architectural property that ties this together is that no value reaches a downstream system without complete provenance. The rater, the policy administration system, the workflow platform, the underwriting workbench all receive values that come with their full lineage. That is what allows the 100 percent contractual accuracy guarantee to mean something. The guarantee is not "the model is always right." The guarantee is "every value is source-linked, validated, and attested, and where any of those steps did not clear, a human expert resolved it before delivery."
The same property is what produces the operational outcomes that matter in 2026. Submission turnaround time in commercial P&C drops because underwriters stop hand-checking the easy fields. Underwriter capacity grows because the layer of clerical reconciliation that used to take 70 to 90 minutes per submission becomes a 5 to 10 minute review of the few items the system flagged. The 85 percent faster submission processing and the 32 percent more GWP per underwriter that Pibit clients report are downstream of the architecture, not standalone claims.
An eight-point provenance rubric for evaluating any AI underwriting vendor
A CUO, a Head of Underwriting Operations, an Underwriting Technology Lead, or a Director of Process Excellence evaluating an AI underwriting vendor in 2026 should ask the following eight questions. Each maps directly to a provenance element and to a real risk that materializes when the answer is weak.
1. For any field on any submission, can you show me the source document, the page, and the bounding box on that page?
A weak answer is "we can usually point to the document." A production answer is a UI demonstration on a live submission, not a slide.
2. Are confidence scores calibrated, and are they at the field level?
A weak answer is "the model is 95 percent accurate." A production answer is a calibration curve showing predicted versus observed accuracy at production-distribution submissions, plus field-level scores rather than batch-level scores.
3. What validations run automatically before a value is delivered, and how are validation outcomes recorded?
A weak answer is "we have rules." A production answer is a documented validation library mapped to LOB, document type, and field, plus a sample provenance record showing rule outcomes.
4. When a human reviews a value, what is captured?
A weak answer is "we have a review queue." A production answer is reviewer identity, timestamp, action, and an immutable bind to the extraction record.
5. Is the provenance record immutable, and how long is it retained?
A weak answer is "we log everything." A production answer is a write-once architecture with a documented retention policy that meets state insurance department, NAIC Model Law, and reinsurance treaty audit expectations.
6. Can the provenance record be exported and ingested by my model risk management, my data lineage tooling, or my regulator on demand?
A weak answer is "we can get you a report." A production answer is an API and an export format that conforms to common audit and lineage tooling.
7. Where is the data processed, and is the processing region under my control?
A weak answer is "in the cloud." A production answer is a customer-controlled cloud region, model isolation per client, and documented data residency commitments.
8. What contractual accuracy guarantee does the vendor stand behind, and what credit applies if the guarantee is missed?
A weak answer is "best efforts." A production answer is a numerical accuracy commitment with a defined credit table and a remediation procedure.
.png)
The pattern across all eight questions is the same. A weak answer is an assertion. A production answer is an artifact. An AI underwriting vendor that cannot produce artifacts under examination is one that has not yet built the system to operate inside a regulated underwriting environment. Carriers and MGAs that select on the basis of demo accuracy without inspecting the artifacts are stacking model risk on top of operational risk.
The unit economics of getting provenance right on a $500M GWP carrier
The case for provenance is not abstract. It compounds across three line items every CUO already tracks.
Loss ratio integrity. Carriers that cannot defend underwriting decisions during reinsurance treaty audits or internal QA reviews carry a portfolio risk that prices itself in. A 700 basis point loss ratio improvement on a $500M GWP book translates to roughly $35M in annual margin, and the path to that improvement starts with risk selection that is provably tied to evidence. Source-linked extraction does not by itself improve loss ratios. It makes loss ratio improvement defensible, which is the precondition for sustaining it.
Operating leverage. The 85 percent reduction in submission processing time and the 32 percent more GWP per underwriter that Pibit clients report are direct consequences of the human-in-the-loop layer reviewing only flagged values, not every value. On a $500M GWP carrier handling 25,000 to 40,000 submissions a year, the time savings translate to a meaningful capacity expansion without headcount growth. Capacity expansion in a softening market protects hit ratio and renewal retention, both of which feed directly back into the loss ratio.
Audit and examination cost. A documented field-level provenance posture compresses examination cycles, reduces external audit fees, and lowers the cost of evidence production. Carriers that have lived through a state insurance department market conduct exam involving AI-influenced workflows already know that the highest cost of those exams is the engineering and operations time spent reconstructing evidence after the fact. A system that produces evidence by default eliminates that cost line.

The dollar story is straightforward. The cost of operating without field-level provenance is not a single number. It is a distribution. In the median case, the carrier carries silent inaccuracy, accepts elevated touch labor, and absorbs higher audit cost. In the tail, the carrier discovers an inaccurate extraction after a claim is litigated, after a treaty audit, or after a regulatory examination, and the cost is a multiple of the steady-state operating savings.
That distribution is why CUOs in 2026 are treating provenance as a board-level question rather than a vendor diligence checkbox.
Why underwriting services are becoming AI-native
The practical implication is that carriers do not just need better extraction software. They need a different operating model for underwriting work.
For decades, the service layer around underwriting has been human-heavy. Offshore teams and BPO providers helped carriers process submissions, key data, reconcile documents, and prepare files for underwriters. That model created capacity, but it also introduced the same issues every underwriting operations leader knows: training cycles, quality variance, handoffs, rework, and limited auditability at the field level.
Generic AI does not solve that by itself. A model that reads documents and returns a clean summary still leaves the carrier with the hardest questions. Which fields are reliable? Which ones conflict? Which values were validated? Which ones need expert review? Where is the source evidence? What changed before the data reached the rater, workbench, or policy system?
That is where AI-native underwriting services are different.
An AI-native service is not a manual team with AI tools on the side. It is a governed operating layer where specialised extraction models assemble the data, agentic QA checks it across documents and external sources, and insurance experts review only the values that require judgment or attestation.
The work is still service-backed, but the service is organized around provenance, validation, and exception handling rather than manual rekeying.
The result is not automation for its own sake. It is underwriting data that arrives faster, with a chain of evidence attached to every field.
What "production-ready" looks like in 2026
The 2026 production standard for AI underwriting has three properties that map to the architectural and operational story above.
The first is source-linked output by default. Every value carries its lineage. Underwriters do not have to ask for it, and engineering does not have to reconstruct it.
The second is calibrated, field-level confidence with explicit thresholds. The system is honest about which values it is sure of, and the carrier sets the threshold below which a human expert reviews. The threshold is documented, configurable per LOB, and reportable.
The third is a contractual accuracy guarantee that is meaningful. A 100 percent contractual accuracy posture, backed by a three-layer architecture and credit terms, is materially different from a 95 percent or 99 percent figure asserted in a demo. Both as a procurement signal and as a model risk management artifact, the contractual structure is what makes the vendor selectable.
Pibit.AI built CURE™ with these three properties as design constraints rather than as features. That is why the platform supports the 100 percent contractual accuracy guarantee, why a 95 percent extraction accuracy headline is not production accuracy, and why the agentic AI architecture in underwriting operates the way it does. Carriers and MGAs evaluating any AI underwriting vendor in 2026 should hold every option to the same standard.
The market is past the era when a benchmark number could carry a deal. In 2026, the deciding question is the audit trail.
Frequently Asked Questions

Field-level provenance is the property that every value an AI underwriting system produces carries its complete lineage at the granularity of the individual field. The lineage includes the source document, page and coordinate location, extraction model and version, calibrated confidence score, transformations applied, validator outcomes, reviewer attestation, and downstream output destinations. It is the standard that separates a defensible underwriting workflow from one that asserts accuracy without evidence.
A headline extraction accuracy figure measures aggregate field correctness on a benchmark or sample. Production submissions are heterogeneous and complex, and even a high benchmark accuracy does not predict accuracy on a 200-page commercial property submission with eleven attachments. Provenance is what allows an underwriter, an auditor, a reinsurer, or a regulator to defend every value the system delivered, including the values where the model was uncertain and a human expert intervened. Without provenance, accuracy is a marketing number rather than an audit artifact.
The CURE™ platform uses a three-layer architecture: specialised extraction, agentic quality assurance, and human expert review. Every value is bound to its source document, page, and coordinate at extraction time and carries a calibrated confidence score. Agentic services run cross-field and cross-source validations and record the outcomes. Human experts review any value that does not clear the agentic layer with sufficient confidence and attest to the result. Provenance records are immutable, queryable, and exportable, which is what makes the 100 percent contractual accuracy guarantee meaningful in production.
Founding Member - AI


.png)

.png)
Ready to optimize



